Hadoop can be a great complement to existing data warehouse platforms, such as Teradata, as it naturally helps to address two key storage challenges:
- Managing large volumes of historical or archival data.
- Handling data from non-standard or un-structured sources
The purpose of this article is to detail some of the key integration points and to show how data can be easily exchanged for enrichment between the two platforms.
As a data integrator who is familiar with RDBMS systems and is new to the Hadoop platform, I was looking for a simple way (i.e. “SQL-way”) to exchange data with Teradata. Fortunately, it was just a matter identifying the tools and connecting the dots.
Using pre-built adapters (Teradata Connector for Hadoop, Hortonworks Teradata Connector), SQL-based protocols for data exchange (Sqoop and Hive) and a GUI interface for Apache Hadoop (HUE, Oozie), simple workflows can be created to deliver big value.
First, lets review the key components:
- Teradata Connector for Hadoop (TDCH). Teradata’s adapter for moving data to\from Hadoop, including data-type mapping, parallel processing capabilities and native loading options.
- Hortonworks Teradata Connector (HTC). A Sqoop wrapper for TDCH that implements standard data exchange syntax for Hadoop.
- Apache Sqoop. A tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases.
- Apache Hive. An Apache project that extends a logical SQL structure over HDFS and supports query using a language called HiveQL.
- Apache Oozie. A workflow scheduler system to manage Apache Hadoop jobs.
Although the parts are many, the majority of work was performed within HUE, which provided XML and script generation as well as a graphic test environment and logging capabilities.
Step 1: Setup
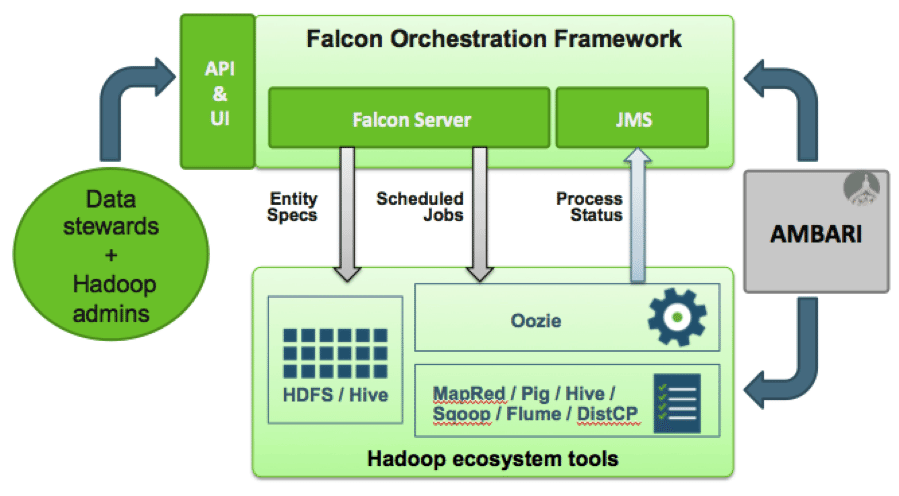
The framework that will co-ordinate the data movement and manipulation process is the Oozie workflow engine, so it is here that the configuration begins.
An Oozie workflow consists of an application (deployment) folder and configuration files (workflow.xml and job.properties) that provide the processing instructions and variable definitions for the workflow job.
In HDFS, the application folder td_oozie_demo and lib sub-directories were created by the hue user account.
# su - hue # hadoop fs –mkdir td_oozie_demo # hadoop fs –mkdir td_oozie_demo/lib
Supporting JAR files for each of the technologies we will leverage can be placed in the “lib” sub-directory.
Below is the list of supporting JAR files with relative source locations:
| # /usr/lib/sqoop/lib |
| /td_oozie_demo/lib/avro-1.5.3.jar |
| /td_oozie_demo/lib/avro-mapred-1.5.3.jar |
| /td_oozie_demo/lib/commons-io-1.4.jar |
| /td_oozie_demo/lib/snappy-java-1.0.3.2.jar |
| /td_oozie_demo/lib/sqoop-1.4.4.2.0.6.0-76.jar |
| # /usr/lib/hive/lib |
| /td_oozie_demo/lib/antlr-runtime-3.4.jar |
| /td_oozie_demo/lib/datanucleus-api-jdo-3.2.1.jar |
| /td_oozie_demo/lib/datanucleus-core-3.2.2.jar |
| /td_oozie_demo/lib/derby-10.4.2.0.jar |
| /td_oozie_demo/lib/hive-cli-0.12.0.2.0.6.0-76.jar |
| /td_oozie_demo/lib/hive-common-0.12.0.2.0.6.0-76.jar |
| /td_oozie_demo/lib/hive-exec-0.12.0.2.0.6.0-76.jar |
| /td_oozie_demo/lib/hive-metastore-0.12.0.2.0.6.0-76.jar |
| /td_oozie_demo/lib/hive-serde-0.12.0.2.0.6.0-76.jar |
| /td_oozie_demo/lib/hive-service-0.12.0.2.0.6.0-76.jar |
| /td_oozie_demo/lib/jackson-core-asl-1.7.3.jar |
| /td_oozie_demo/lib/jdo-api-3.0.1.jar |
| /td_oozie_demo/lib/jline-0.9.94.jar |
| /td_oozie_demo/lib/jopt-simple-3.2.jar |
| /td_oozie_demo/lib/libfb303-0.9.0.jar |
| /td_oozie_demo/lib/opencsv-2.3.jar |
| # https://downloads.teradata.com/download/connectivity/teradata-connector-for-hadoop-sqoop-integration-edition |
| /td_oozie_demo/lib/tdgssconfig.jar |
| /td_oozie_demo/lib/teradata-connector-1.1.1-hadoop200.jar |
| /td_oozie_demo/lib/terajdbc4.jar |
| # http://hortonworks.com/products/hdp-2/#add_ons |
| /td_oozie_demo/lib/hortonworks-teradata-connector-1.1.1.2.0.6.1-101.jar |
One more key requirement is to copy the hive-site.xml file to the application folder. This file provides the mapping between the Oozie workflow and the HCatalog metadata store for Hive.
# hadoop fs –cp /usr/lib/hive/conf/hive-site.xml td_oozie_demo/hive-config.xml
Once the initial setup is in place, the remaining steps can be performed in the HUE graphic interface. Note that the workflow.xml file mentioned earlier will be auto-generated during “Step 3: Process Definition”.
Step 2: Configuration
In a default HDP 2.0 installation, the HUE interface can be reached from the following URL: http://<hostname or ip>:8000
From the HUE website, browse to the Oozie Editor and create a new Workflow:

Edit the Workflow properties to specify the application directory – td_oozie_demo – and configuration file – hive-config.xml.

Step 3: Process Definition
The Oozie Editor support several types of workflow “actions” that can be coordinated, for this example we will focus on two types: Hive and Sqoop.
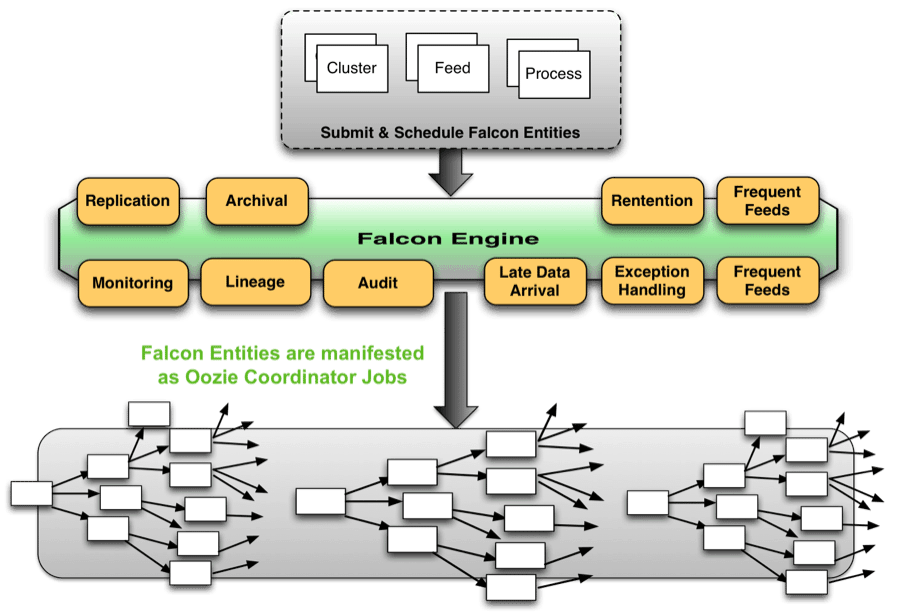
The workflow will consist of the following process steps:
- Hive: Create the target Hive table that will accept import from Teradata
- Sqoop: Perform the import from Teradata to Hive
- Hive: Generate an aggregated result set that enriches imported Teradata records with existing Hive\Hadoop data
- Sqoop: Perform an export of the Hive result set to Teradata
Process step (a) will run the following SQL script – hive_script1.sql:
DROP TABLE IF EXISTS CLIENT; CREATE TABLE CLIENT ( C_CUSTKEY INT, C_NAME STRING, C_ADDRESS STRING, C_NATIONKEY INT, C_PHONE STRING, C_ACCTBAL DOUBLE, C_MKTSEGMENT STRING, C_COMMENT STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
Using the workflow editor, Add a “Hive” action and upload the hive_script1.sql file:

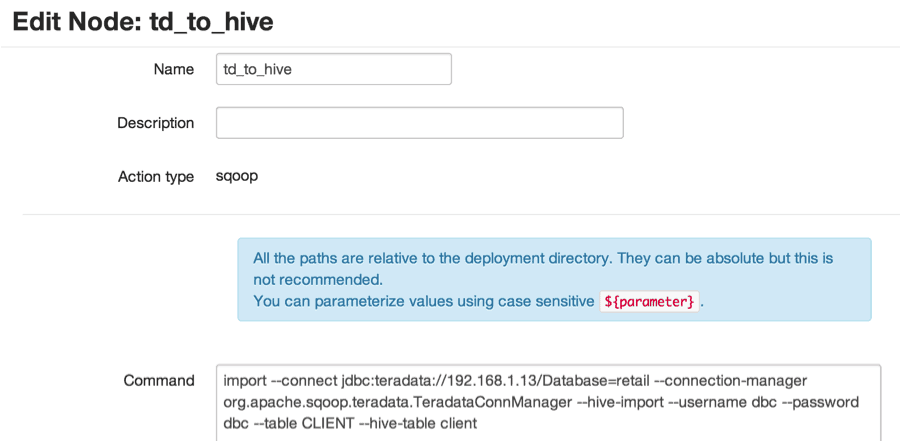
Process step 2 will perform a SQOOP import from the Teradata table “CLIENT” to the Hive table “client” that was created in the previous step.
Using the workflow editor, Add a “Sqoop” action and specify the IMPORT command:
import --connect jdbc:teradata://<HOSTNAME OR IP ADDRESS>/Database=retail --connection-manager org.apache.sqoop.teradata.TeradataConnManager --hive-import --username dbc --password dbc --table CLIENT --hive-table client
Note: This example connects to the Teradata Studio Express 14 VM available from Teradata.
Process step 3 will run the following SQL script – hive_script2.sql – that generates an aggregated result set from the import table (client) and existing tables (contract, item):
DROP TABLE IF EXISTS CUST_BY_YEAR; CREATE TABLE IF NOT EXISTS CUST_BY_YEAR( C_CUSTKEY INT, C_NAME STRING, C_YEAR INT, C_TOTAL_BY_YEAR DOUBLE ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; INSERT OVERWRITE TABLE CUST_BY_YEAR select c.c_custkey, c.c_name, substr(o_orderdate,0,4) AS o_year, sum(l_extendedprice) AS o_year_total FROM client c JOIN contract o ON c.c_custkey = o.o_custkey JOIN item l ON o.o_orderkey = l.l_orderkey GROUP BY c.c_custkey, c.c_name, substr(o_orderdate,0,4);
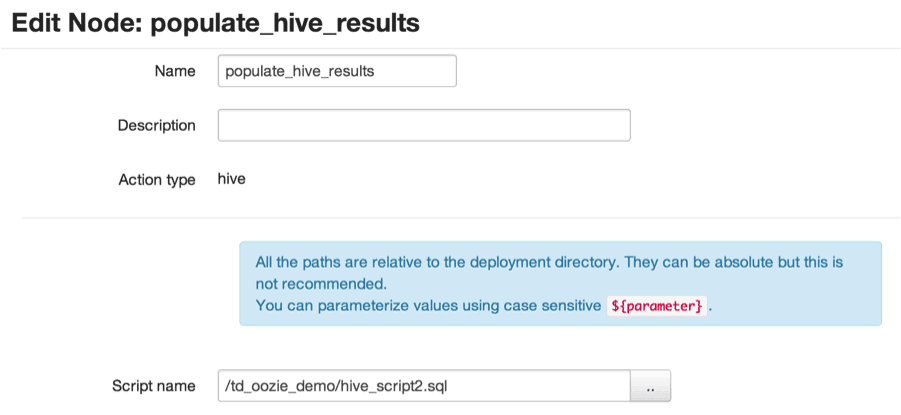
Using the workflow editor, Add a “Hive” action and upload the hive_script2.sql file:
Process step 4 will perform a Sqoop export from the Hive table cust_by_year to the Teradata table HDP_IMPORT.CUST_BY_YEAR.
Using the workflow editor, Add a “Sqoop” action and specify the IMPORT command:
export --connect jdbc:teradata://<HOST OR IP ADDRESS>/Database=HDP_IMPORT --connection-manager org.apache.sqoop.teradata.TeradataConnManager --username dbc --password dbc --table CUST_BY_YEAR --export-dir /apps/hive/warehouse/cust_by_year --input-fields-terminated-by "\t"
Note: The DDL for the target Teradata table CUST_BY_YEAR is:
CREATE SET TABLE HDP_IMPORT.CUST_BY_YEAR ( C_CUSTKEY INTEGER NOT NULL, C_NAME VARCHAR(25) CHARACTER SET LATIN NOT CASESPECIFIC NOT NULL, C_YEAR INTEGER NOT NULL, C_YEARTOTAL DECIMAL(15,2) NOT NULL);

Upon completion of the workflow definition, the following workflow.xml is auto-generated in the Oozie application folder:
<workflow-app name="Teradata Oozie Demo" xmlns="uri:oozie:workflow:0.4">
<global>
<job-xml>/td_oozie_demo/hive-config.xml</job-xml>
</global>
<start to="create_hive_target"/>
<action name="create_hive_target">
<hive xmlns="uri:oozie:hive-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<script>/td_oozie_demo/hive_script1.sql</script>
</hive>
<ok to="td_to_hive"/>
<error to="kill"/>
</action>
<action name="td_to_hive">
<sqoop xmlns="uri:oozie:sqoop-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<command>import --connect jdbc:teradata://192.168.1.13/Database=retail --connection-manager org.apache.sqoop.teradata.TeradataConnManager --hive-import --username dbc --password dbc --table CLIENT --hive-table client</command>
</sqoop>
<ok to="populate_hive_results"/>
<error to="kill"/>
</action>
<action name="populate_hive_results">
<hive xmlns="uri:oozie:hive-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<script>/td_oozie_demo/hive_script2.sql</script>
</hive>
<ok to="hive_to_td"/>
<error to="kill"/>
</action>
<action name="hive_to_td">
<sqoop xmlns="uri:oozie:sqoop-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<command>export --connect jdbc:teradata://192.168.1.13/Database=HDP_IMPORT --connection-manager org.apache.sqoop.teradata.TeradataConnManager --username dbc --password dbc --table CUST_BY_YEAR --export-dir /apps/hive/warehouse/cust_by_year --input-fields-terminated-by "\t"</command>
</sqoop>
<ok to="end"/>
<error to="kill"/>
</action>
<kill name="kill">
<message>Action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
Step 4: Testing and Execution
Using the Oozie Workflow Manager, the newly created job can be submitted for execution.

The workflow actions can be tracked and analyzed, each action maintaining it’s own process log file. The interface also provides a “Rerun” option that allows for unit testing should any action fail to complete.

Final thoughts
In this example, records from Teradata are imported to Hadoop. SQL-like processing occurs in a series of Oozie Workflow “actions” in the Hadoop platform. A smaller, aggregated result is then returned to Teradata.
By leveraging Hadoop and its SQL integration points, it is possible to off-load storage and processing demands from a data warehouse to a Big Data store.
Integration between Teradata and the Hortonworks Data Platform (HDP) is not limited to the example in this article. SQL-H integration for “on-demand” data exchange with Hadoop, Viewpoint \ Ambari integration for monitoring and management of Hadoop are both powerful tools that are available within the Teradata suite of products.
This article’s focus was on the integration features within HDP and these same tools (Oozie, Sqoop and Hive) can interact with almost any RDBMS that supports JDBC.
Additional Notes:
This integration demo was setup between two downloadable VMs:
Data for the Hive tables, “contract” and “item”, were originally sourced from the Teradata Studio Express “retail” DB, using SQOOP.
sqoop import -libjars ${LIB_JARS} --connect jdbc:teradata://<HOST OR IP ADDRESS>/Database=retail --connection-manager org.apache.sqoop.teradata.TeradataConnManager --hive-import --username dbc --password dbc --table ITEM --hive-table item
sqoop import -libjars ${LIB_JARS} --connect jdbc:teradata://<HOST OR IP ADDRESS/Database=retail --connection-manager org.apache.sqoop.teradata.TeradataConnManager --hive-import --username dbc --password dbc --table CONTRACT --hive-table contract
Target Hive table DDL for the Teradata Retail tables CONTRACT and ITEMS:
CREATE TABLE IF NOT EXISTS ITEM (l_orderkey int, l_partkey int, l_suppkey int, l_linenumber int, l_quantity double, l_extendedprice double, l_discount double, l_tax double, l_returnflag string, l_linestatus string, l_shipdate string, l_commitdate string, l_receiptdate string, l_shipinstruct string, l_shipmode string, l_comment string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’; CREATE TABLE IF NOT EXISTS CONTRACT (o_orderkey int, o_custkey int, o_orderstatus string, o_totalprice double, o_orderdate string, o_orderpriority string, o_clerk string, o_shippriority int, o_comment string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’;
See documentation from Hortonworks related to the Hortonworks Teradata Connector for more information on Sqoop integration with Teradata.
The post Round-trip Data Enrichment between Teradata and Hadoop appeared first on Hortonworks.
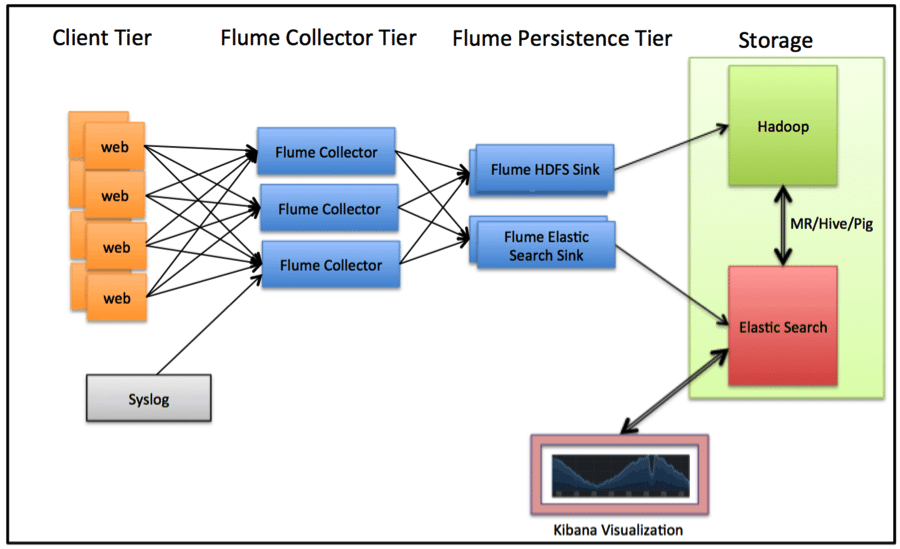








 As Apache Hadoop has taken its role in enterprise data architectures, a host of open source projects have been contributed to the Apache Software Foundation (ASF) by both vendors and users alike that greatly expand Hadoop’s capabilities as an enterprise data platform. Many of the “committers” for these open source projects are Hortonworks employees. For those unfamiliar with the term “committer”, they are the talented individuals who devote their time and energy on specific Apache projects adding features, fixing bugs, and reviewing and approving changes submitted by others interested in contributing to the project.
As Apache Hadoop has taken its role in enterprise data architectures, a host of open source projects have been contributed to the Apache Software Foundation (ASF) by both vendors and users alike that greatly expand Hadoop’s capabilities as an enterprise data platform. Many of the “committers” for these open source projects are Hortonworks employees. For those unfamiliar with the term “committer”, they are the talented individuals who devote their time and energy on specific Apache projects adding features, fixing bugs, and reviewing and approving changes submitted by others interested in contributing to the project.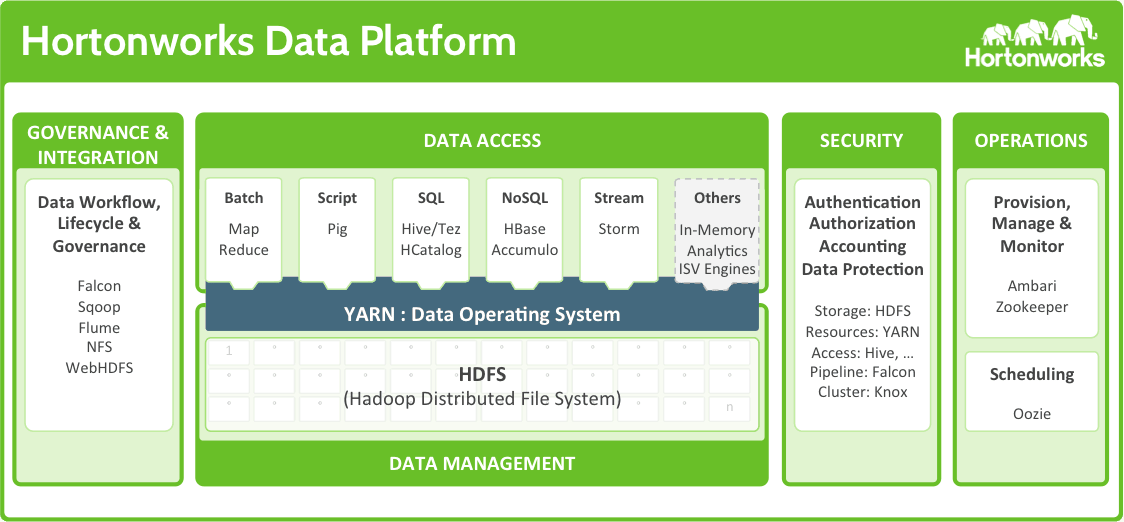
 In February 2014, the
In February 2014, the 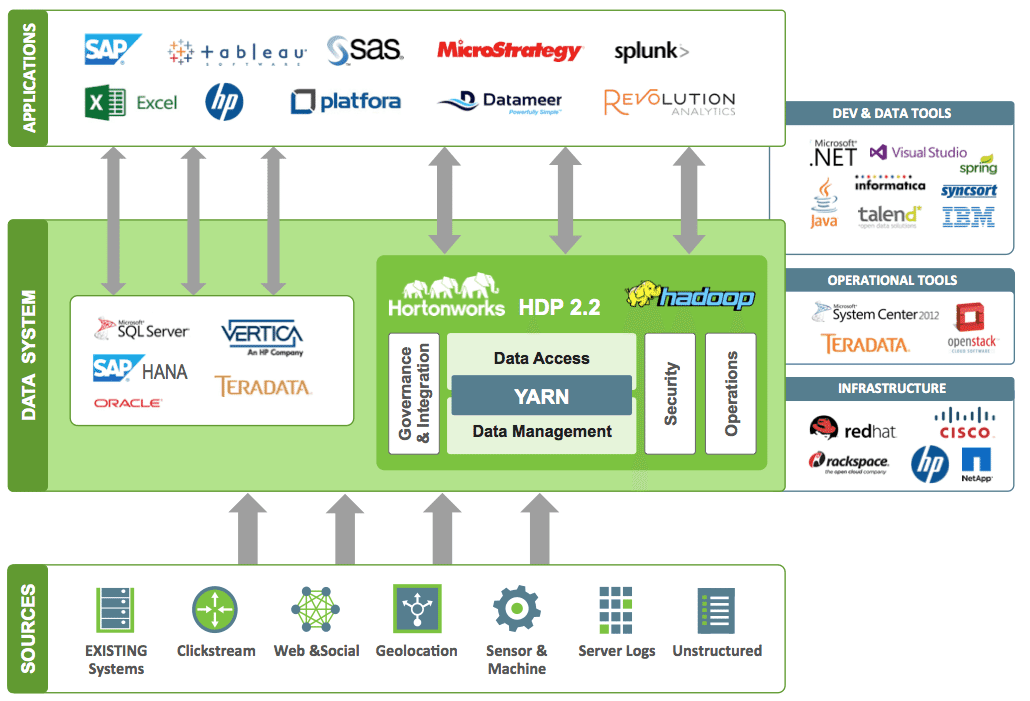





 HDP delivers on the commitments made last year with the final phase of the
HDP delivers on the commitments made last year with the final phase of the 

 We are excited to announce that the
We are excited to announce that the  It gives me great pleasure to
It gives me great pleasure to