Whether you were busy finishing up last minute Christmas shopping or just taking time off for the holidays, you might have missed that Hortonworks released the Stinger Phase 3 Technical Preview back in December. The Stinger Initiative is Hortonworks’ open roadmap to making Hive 100x faster while adding standard SQL. Here we’ll discuss 3 great reasons to give Stinger Phase 3 Preview a try to start off the new year.
Reason 1: It’s The Fastest Hive Yet
Whether you want to process more data or lower your time-to-insight, the benefits of a faster Hive speak for themselves. Stinger Phase 3 brings 3 key new components into Hive that lead to a massive speed boost.
| Component | Benefit |
| Tez | A modern implementation of Map/Reduce. New Tez operators simplify and accelerate complex data processing natively in Hadoop. |
| Tez Service | Maintains warm containers and caches key information to allow fast query launch. |
| Vectorized Query | New execution engine that takes advantage of modern hardware architectures to accelerate computations of data in memory up to 100x. |
What does it add up to? To find out we compared Stinger Phase 3 Preview head-to-head against Hive 12 on the same hardware and over the same dataset.

In this broad-based benchmark including both large reporting type queries as well as more targeted drill-down queries, Stinger Technical Preview shows an average 2.7x speedup versus Hive 12. Remember that Hive 12 includes all the performance benefits that have gone into Stinger Phases 1 and 2, and is the fastest Hive generally available today.
We also did some limited comparisons between Hive on Tez and Hive 10. Hive 10 pre-dates the Stinger initiative and its focus on improving Hive performance.

In this limited subset of queries we see speedups ranging from 5x to 40x going from Hive 10 to Hive on Tez.
Configuration Details
| Hardware: | Software: |
20 physical nodes, each with:
|
|
| Data: | Queries: |
|
|
Reason 2: Hive is now Interactive
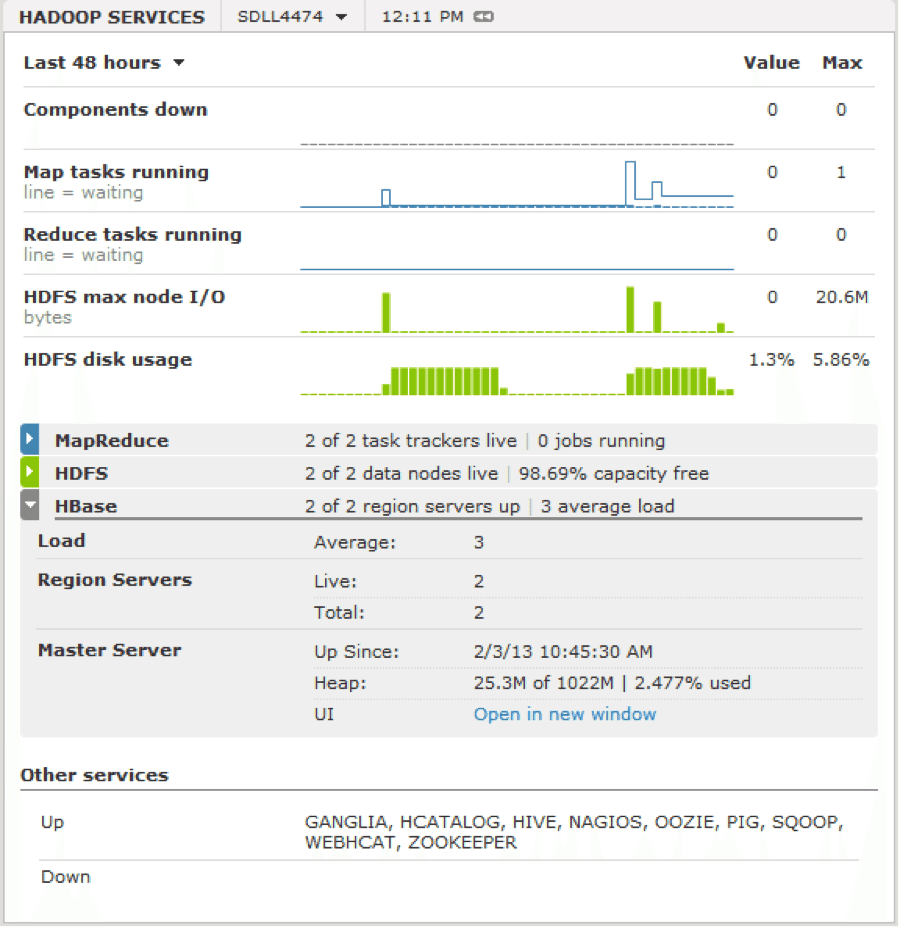
Stinger Phase 3 Preview introduces the Tez Service, a persistent service that runs as a YARN Application Master. The Tez Service’s job is to facilitate fast query launch, and does this in two ways: First, the Tez Service keeps hot containers on standby to ensure fast query launch.
Second, the Tez Service caches key information such as split calculations. Any time data in Hadoop is processed, maps are assigned to splits of files on the filesystem in order to divide-and-conquer the work. This involves querying the NameNode to identify where the data is physically located and can take several seconds for large datasets. Because Tez Service caches this data, subsequent queries over the same data launch much faster.

Let’s take a look at a few examples of how the Tez Service helps.
|
Query |
Tez Cold (s) |
Tez Warm (s) |
Speedup from Tez Service (s) |
| query27 | 24.3 | 8.8 | 15.5 |
| query79 | 80.9 | 45.2 | 35.8 |
Some example speedups using Tez Service.
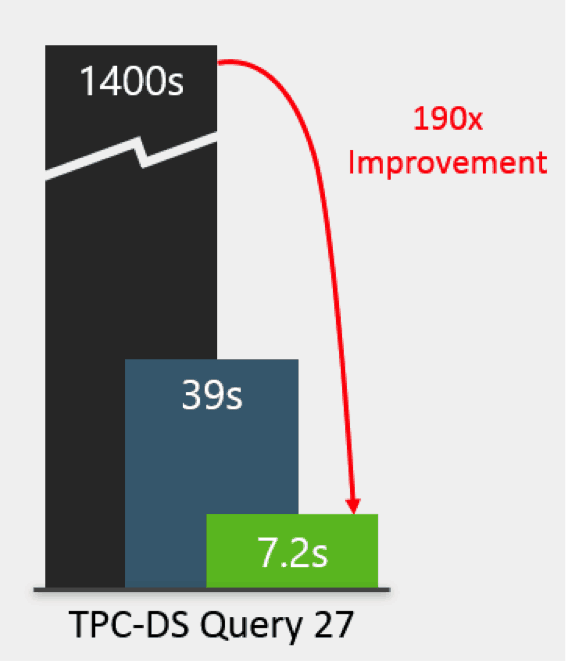
Query 27 is a simple star-schema join involving one fact table and many dimension tables. When Tez Service has cached data and has warm containers, time to execute falls by more than 50% to under 10 seconds, which many people regard as the bar for “interactive query”.
Query 79 is a more complex fact-to-fact join that addresses much more data. Because more data is addressed, caching benefits the query even more, saving more than 30 seconds.

In the results, Hot queries ran an average of 17 seconds faster than cold queries. This is a big deal for queries smaller, interactive queries because now Hive is able to run queries in less than 10 seconds over large datasets, enabling interactive query in Hadoop.
Reason 3: Hive is 100% Community Open Source
At Hortonworks we spend a lot of time talking about Hive but it’s important to remember that Hive is a community effort and represents the hard work of hundreds of individuals who either contribute privately or represent one of more than 10 companies that contribute to Hive. Through this collective effort, Hive is quickly becoming the most robust, mature and secure SQL solution for Hadoop. Apache Hive is the only SQL solution for Hadoop supported by every major Hadoop distribution. Choosing Hive means 100% Community Open Source and 0% lock-in.
Try It For Yourself
We hope you’ll try the Stinger Phase 3 Preview for yourself. All you need is an HDP 2.0 cluster or Sandbox. To get started, follow the instructions on the announcement blog post. As always, if you have questions or need help, head to the Hortonworks Forums for tips and advice.
The post 3 Reasons to try Stinger Phase 3 Technical Preview appeared first on Hortonworks.



 We’re kicking off 2014 with an evolution to our Modern Data Architecture webinar series. Last year we focused on how your existing technologies integrate with Apache Hadoop. This year we will focus on use cases for how Hadoop and your existing technologies are being used to get real value in the enterprise. Join Hortonworks, along with
We’re kicking off 2014 with an evolution to our Modern Data Architecture webinar series. Last year we focused on how your existing technologies integrate with Apache Hadoop. This year we will focus on use cases for how Hadoop and your existing technologies are being used to get real value in the enterprise. Join Hortonworks, along with 
 We founded
We founded